
Panduan Robots.txt
Manfaatkan kekuatan robots.txt: Pelajari cara menggunakan robots.txt untuk memblokir URL yang tidak diperlukan dan meningkatkan strategi SEO situs web Anda.
Memahami cara menggunakan file robots.txt sangat penting untuk strategi SEO situs web mana pun. Kesalahan dalam file ini dapat memengaruhi cara situs web Anda dirayapi dan tampilan halaman Anda dalam pencarian. Di sisi lain, melakukannya dengan benar dapat meningkatkan efisiensi perayapan dan mengurangi masalah perayapan.
Google baru-baru ini mengingatkan pemilik situs web tentang pentingnya menggunakan robots.txt untuk memblokir URL yang tidak diperlukan.
Halaman-halaman tersebut mencakup halaman tambah ke keranjang belanja, login, atau checkout. Namun pertanyaannya adalah – bagaimana cara menggunakannya dengan benar?
Dalam artikel ini, kami akan memandu Anda ke setiap nuansa tentang cara melakukannya.
Daftar Isi
- 1.Apa itu Robots.txt?
- 2.Urutan Prioritas Dalam Robots.txt
- 3.Mengapa Robots.txt Penting dalam SEO?
- 4.Kapan Menggunakan Robots.txt
- 5.Pemecahan Masalah Robots.txt
- 6.Manajemen Robots.txt Terpusat
Apa itu Robots.txt?
Robots.txt adalah berkas teks sederhana yang berada di direktori root situs Anda dan memberi tahu perayap apa yang harus dirayapi.
Tabel di bawah ini menyediakan referensi cepat ke perintah utama robots.txt .
| Direktif | Keterangan |
| Agen pengguna | Menentukan perayap mana yang akan menerapkan aturan. Lihat token agen pengguna . Menggunakan * menargetkan semua perayap. |
| Melarang | Mencegah URL tertentu untuk dirayapi. |
| Mengizinkan | Mengizinkan URL tertentu untuk dirayapi, bahkan jika direktori induk tidak diizinkan. |
| Peta Situs | Menunjukkan lokasi Peta Situs XML Anda dengan membantu mesin pencari menemukannya. |
Ini adalah contoh robot.txt dari ikea.com dengan beberapa aturan.
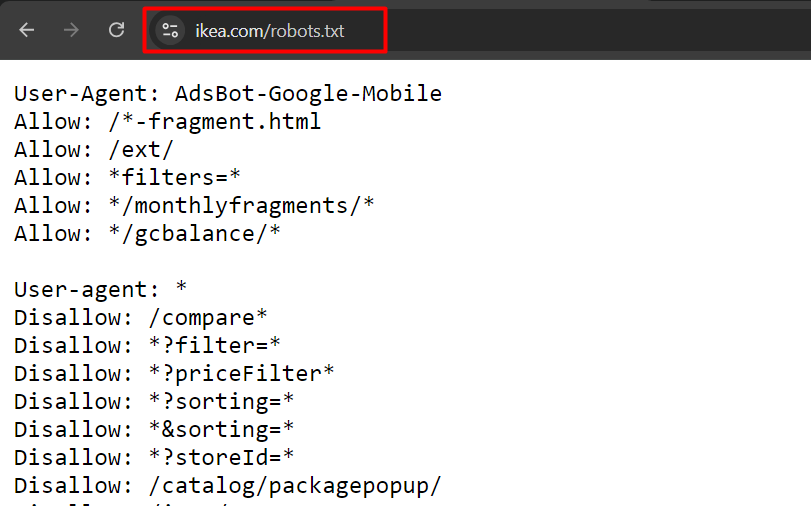 Contoh robots.txt dari ikea.com
Contoh robots.txt dari ikea.com
Perhatikan bahwa robots.txt tidak mendukung ekspresi reguler penuh dan hanya memiliki dua karakter pengganti:
- Tanda bintang (*), yang cocok dengan 0 atau lebih rangkaian karakter.
- Tanda dolar ($), yang cocok dengan akhir URL.
Perlu diperhatikan juga bahwa aturannya peka huruf besar/kecil, misalnya, “filter=” tidak sama dengan “Filter=”.
Urutan Prioritas Dalam Robots.txt
Saat menyiapkan file robots.txt, penting untuk mengetahui urutan mesin pencari memutuskan aturan mana yang akan diterapkan jika terjadi aturan yang bertentangan.
Mereka mengikuti dua aturan utama berikut:
1. Aturan Paling Spesifik
Aturan yang mencocokkan lebih banyak karakter di URL akan diterapkan. Misalnya:
User-agent: *
Disallow: /downloads/
Allow: /downloads/free/Dalam kasus ini, aturan “Izinkan: /downloads/gratis/” lebih spesifik daripada “Larang: /downloads/” karena menargetkan subdirektori.
Google akan mengizinkan perayapan subfolder “/downloads/free/” tetapi memblokir semua yang lain di bawah “/downloads/.”
2. Aturan yang Paling Tidak Membatasi
Ketika beberapa aturan sama-sama spesifik, misalnya:
User-agent: *
Disallow: /downloads/
Allow: /downloads/Google akan memilih yang paling tidak membatasi. Ini berarti Google akan mengizinkan akses ke /downloads/.
Mengapa Robots.txt Penting dalam SEO?
Memblokir halaman yang tidak penting dengan robots.txt membantu Googlebot memfokuskan anggaran perayapannya pada bagian situs web yang penting dan pada perayapan halaman baru. Ini juga membantu mesin pencari menghemat daya komputasi, yang berkontribusi pada keberlanjutan yang lebih baik .
Bayangkan Anda memiliki toko daring dengan ratusan ribu halaman. Ada beberapa bagian situs web seperti halaman yang difilter yang mungkin memiliki versi yang tak terbatas jumlahnya.
Kapan Menggunakan Robots.txt
Sebagai aturan umum, Anda harus selalu bertanya mengapa halaman tertentu ada, dan apakah halaman tersebut memiliki sesuatu yang berharga untuk dijelajahi dan diindeks oleh mesin pencari.
Kalau kita bertolak dari prinsip ini, tentu kita harus selalu menghalangi:
- URL yang berisi parameter kueri seperti:
- Pencarian internal.
- URL navigasi bersegi dibuat dengan memfilter atau mengurutkan opsi jika URL tersebut bukan bagian dari struktur URL dan strategi SEO.
- URL tindakan seperti tambahkan ke daftar keinginan atau tambahkan ke keranjang.
- Bagian pribadi situs web, seperti halaman login.
- File JavaScript tidak relevan dengan konten atau rendering situs web, seperti skrip pelacakan.
- Memblokir scraper dan chatbot AI untuk mencegah mereka menggunakan konten Anda untuk tujuan pelatihan mereka.
Mari kita lihat contoh bagaimana Anda dapat menggunakan robots.txt untuk setiap kasus.
1. Blokir Halaman Pencarian Internal
Langkah yang paling umum dan mutlak diperlukan adalah memblokir URL pencarian internal agar tidak dirayapi oleh Google dan mesin pencari lainnya , karena hampir setiap situs web memiliki fungsi pencarian internal.
Di situs WordPress, biasanya parameternya adalah “s”, dan URL-nya terlihat seperti ini:
https://www.example.com/?s=googleGary Illyes dari Google telah berulang kali memperingatkan untuk memblokir URL “tindakan” karena dapat menyebabkan Googlebot merayapinya tanpa batas bahkan pada URL yang tidak ada dengan kombinasi yang berbeda.
Berikut adalah aturan yang dapat Anda gunakan di robots.txt Anda untuk memblokir URL tersebut agar tidak dirayapi:
User-agent: *
Disallow: *s=*- Baris User-agent: * menetapkan bahwa aturan berlaku untuk semua perayap web, termasuk Googlebot, Bingbot, dll.
- Baris Disallow: *s=* memberi tahu semua perayap untuk tidak merayapi URL apa pun yang berisi parameter kueri “s=.” Karakter pengganti “*” berarti karakter tersebut dapat mencocokkan urutan karakter apa pun sebelum atau sesudah “s= .” Namun, karakter tersebut tidak akan mencocokkan URL dengan huruf kapital “S” seperti “/?S=” karena peka huruf besar/kecil.
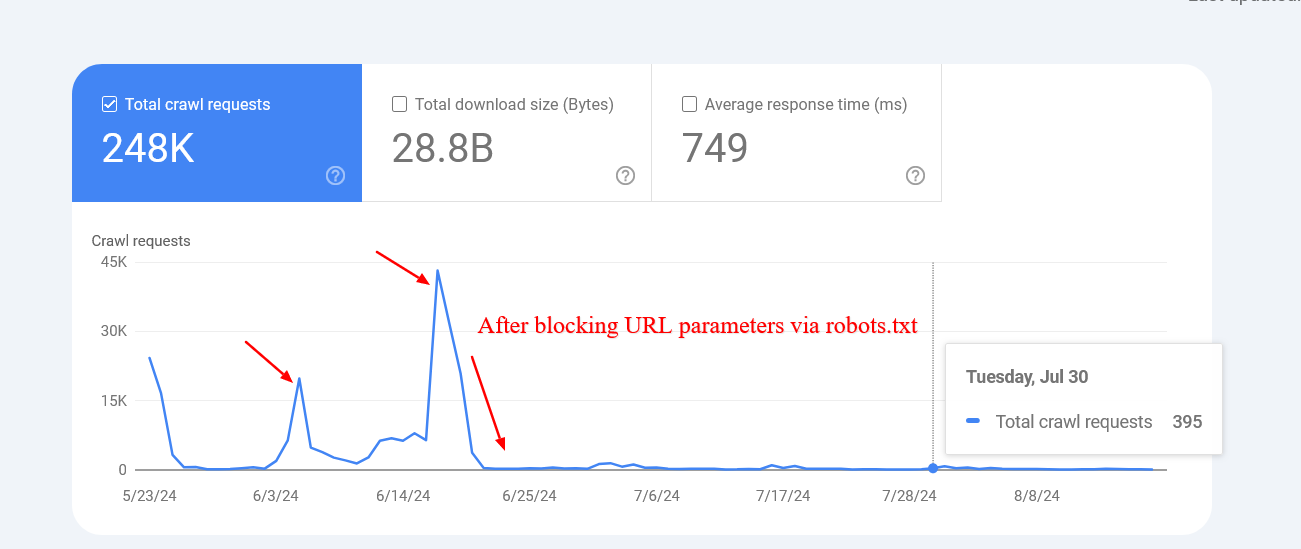
Berikut adalah contoh situs web yang berhasil secara drastis mengurangi perayapan URL pencarian internal yang tidak ada setelah memblokirnya melalui robots.txt.
Tangkapan layar dari laporan statistik perayapan
Perlu diingat bahwa Google mungkin mengindeks halaman-halaman yang diblokir tersebut , tetapi Anda tidak perlu mengkhawatirkannya karena halaman-halaman tersebut akan dihapus seiring berjalannya waktu.
2. Blokir URL Navigasi Bersegi
Navigasi berfaset merupakan bagian integral dari setiap situs web e-commerce. Ada beberapa kasus di mana navigasi berfaset merupakan bagian dari strategi SEO dan ditujukan untuk menentukan peringkat pencarian produk umum.
Misalnya, Zalando menggunakan URL navigasi bersegi untuk pilihan warna guna menentukan peringkat kata kunci produk umum seperti “kaus abu-abu”.
Akan tetapi, dalam kebanyakan kasus, hal ini tidak terjadi, dan parameter filter hanya digunakan untuk memfilter produk, sehingga menghasilkan lusinan halaman dengan konten duplikat.
Secara teknis, parameter tersebut tidak berbeda dari parameter pencarian internal dengan satu perbedaan karena mungkin ada beberapa parameter. Anda perlu memastikan untuk melarang semuanya.
Misalnya, jika Anda memiliki filter dengan parameter berikut “sortby,” “color,” dan “price,” Anda dapat menggunakan kumpulan aturan ini:
User-agent: *
Disallow: *sortby=*
Disallow: *color=*
Disallow: *price=*Berdasarkan kasus spesifik Anda, mungkin ada lebih banyak parameter, dan Anda mungkin perlu menambahkan semuanya.
Bagaimana dengan Parameter UTM?
Parameter UTM digunakan untuk tujuan pelacakan.
Seperti yang dinyatakan John Mueller dalam postingan Reddit-nya , Anda tidak perlu khawatir tentang parameter URL yang tertaut ke halaman Anda secara eksternal.
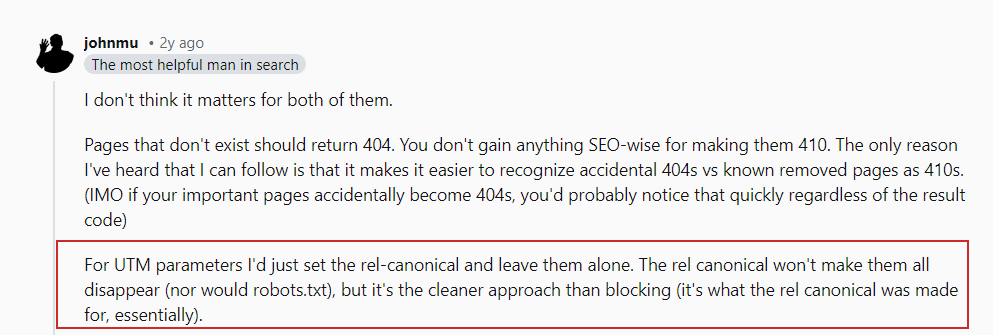 John Mueller tentang parameter UTM
John Mueller tentang parameter UTM
Pastikan untuk memblokir semua parameter acak yang Anda gunakan secara internal dan hindari menautkan secara internal ke halaman tersebut, misalnya, menautkan dari halaman artikel Anda ke halaman pencarian Anda dengan halaman permintaan pencarian “https://www.example.com/?s=google.”
3. Blokir URL PDF
Katakanlah Anda memiliki banyak dokumen PDF, seperti panduan produk, brosur, atau makalah yang dapat diunduh, dan Anda tidak ingin dokumen tersebut dirayapi.
Berikut adalah aturan robots.txt sederhana yang akan memblokir bot mesin pencari mengakses dokumen tersebut:
User-agent: *
Disallow: /*.pdf$Baris “Disallow: /*.pdf$” memberi tahu perayap untuk tidak merayapi URL apa pun yang diakhiri dengan .pdf.
Dengan menggunakan /*, aturan tersebut cocok dengan jalur mana pun di situs web. Akibatnya, URL apa pun yang diakhiri dengan .pdf akan diblokir dari perayapan.
Jika Anda memiliki situs web WordPress dan ingin melarang PDF dari direktori unggahan tempat Anda mengunggahnya melalui CMS, Anda dapat menggunakan aturan berikut:
User-agent: *
Disallow: /wp-content/uploads/*.pdf$
Allow: /wp-content/uploads/2024/09/allowed-document.pdf$Anda dapat melihat bahwa kami memiliki aturan yang saling bertentangan di sini.
Jika terjadi konflik aturan, aturan yang lebih spesifik akan diutamakan. Artinya, baris terakhir memastikan bahwa hanya file tertentu yang terletak di folder “wp-content/uploads/2024/09/allowed-document.pdf” yang boleh dirayapi.
4. Blok Direktori A
Misalnya, Anda memiliki titik akhir API tempat Anda mengirimkan data dari formulir. Kemungkinan formulir Anda memiliki atribut tindakan seperti action=”/form/submissions/.”
Masalahnya adalah Google akan mencoba merayapi URL tersebut, /form/submissions/, yang mungkin tidak Anda inginkan. Anda dapat memblokir URL ini agar tidak dirayapi dengan aturan ini:
User-agent: *
Disallow: /form/Dengan menentukan direktori dalam aturan Disallow, Anda memberi tahu perayap untuk menghindari perayapan semua halaman di bawah direktori tersebut, dan Anda tidak perlu lagi menggunakan karakter pengganti (*), seperti “/form/*.”
Perlu diingat bahwa Anda harus selalu menentukan jalur relatif dan tidak pernah menentukan URL absolut, seperti “https://www.example.com/form/” untuk perintah Disallow dan Allow.
Berhati-hatilah untuk menghindari aturan yang salah bentuk. Misalnya, menggunakan /form tanpa garis miring di akhir juga akan cocok dengan halaman /form-design-examples/, yang mungkin merupakan halaman di blog Anda yang ingin Anda indeks.
5. Blokir URL Akun Pengguna
Jika Anda memiliki situs web e-commerce, kemungkinan besar Anda memiliki direktori yang dimulai dengan “/myaccount/,” seperti “/myaccount/orders/” atau “/myaccount/profile/.”
Karena halaman teratas “/myaccount/” merupakan halaman masuk yang ingin diindeks dan ditemukan oleh pengguna dalam penelusuran, Anda mungkin ingin melarang subhalaman dirayapi oleh Googlebot.
Anda dapat menggunakan aturan Disallow dalam kombinasi dengan aturan Allow untuk memblokir semua yang ada di direktori “/myaccount/” (kecuali halaman /myaccount/).
User-agent: *
Disallow: /myaccount/
Allow: /myaccount/$
Dan sekali lagi, karena Google menggunakan aturan yang paling spesifik, ia akan melarang apa pun yang berada di bawah direktori /myaccount/ tetapi hanya mengizinkan halaman /myaccount/ untuk dirayapi.
Berikut ini adalah kasus penggunaan lain dari penggabungan aturan Disallow dan Allow: jika Anda memiliki pencarian di direktori /search/ dan ingin pencarian tersebut ditemukan dan diindeks tetapi memblokir URL pencarian yang sebenarnya:
User-agent: *
Disallow: /search/
Allow: /search/$
6. Blokir File JavaScript yang Tidak Terkait dengan Render
Setiap situs web menggunakan JavaScript, dan banyak dari skrip ini tidak terkait dengan penyajian konten, seperti skrip pelacakan atau yang digunakan untuk memuat AdSense.
Googlebot dapat merayapi dan merender konten situs web tanpa skrip ini. Oleh karena itu, memblokirnya aman dan direkomendasikan, karena menghemat permintaan dan sumber daya untuk mengambil dan mengurainya.
Di bawah ini adalah contoh baris yang tidak mengizinkan contoh JavaScript, yang berisi piksel pelacakan.
User-agent: *
Disallow: /assets/js/pixels.js7. Blokir Chatbot dan Scraper AI
Banyak penerbit khawatir bahwa konten mereka digunakan secara tidak adil untuk melatih model AI tanpa persetujuan mereka, dan mereka ingin mencegah hal ini.
#ai chatbots
User-agent: GPTBot
User-agent: ChatGPT-User
User-agent: Claude-Web
User-agent: ClaudeBot
User-agent: anthropic-ai
User-agent: cohere-ai
User-agent: Bytespider
User-agent: Google-Extended
User-Agent: PerplexityBot
User-agent: Applebot-Extended
User-agent: Diffbot
User-agent: PerplexityBot
Disallow: /#scrapers
User-agent: Scrapy
User-agent: magpie-crawler
User-agent: CCBot
User-Agent: omgili
User-Agent: omgilibot
User-agent: Node/simplecrawler
Disallow: /Di sini, setiap agen pengguna dicantumkan secara individual, dan aturan Disallow: / memberi tahu bot tersebut untuk tidak merayapi bagian mana pun dari situs.
Hal ini, selain mencegah pelatihan AI pada konten Anda, dapat membantu mengurangi beban pada server Anda dengan meminimalkan perayapan yang tidak diperlukan.
Untuk mendapatkan ide tentang bot mana yang harus diblokir, Anda mungkin ingin memeriksa berkas log server Anda untuk melihat perayap mana yang menghabiskan server Anda, dan ingat, robots.txt tidak mencegah akses yang tidak sah.
8. Tentukan URL Peta Situs
Menyertakan URL peta situs Anda dalam file robots.txt membantu mesin pencari menemukan semua halaman penting di situs web Anda dengan mudah. Hal ini dilakukan dengan menambahkan baris tertentu yang mengarah ke lokasi peta situs Anda, dan Anda dapat menentukan beberapa peta situs, masing-masing pada barisnya sendiri.
Sitemap: https://www.example.com/sitemap/articles.xml
Sitemap: https://www.example.com/sitemap/news.xml
Sitemap: https://www.example.com/sitemap/video.xmlTidak seperti aturan Izinkan atau Larang, yang hanya mengizinkan jalur relatif, perintah Peta Situs memerlukan URL lengkap dan absolut untuk menunjukkan lokasi peta situs.
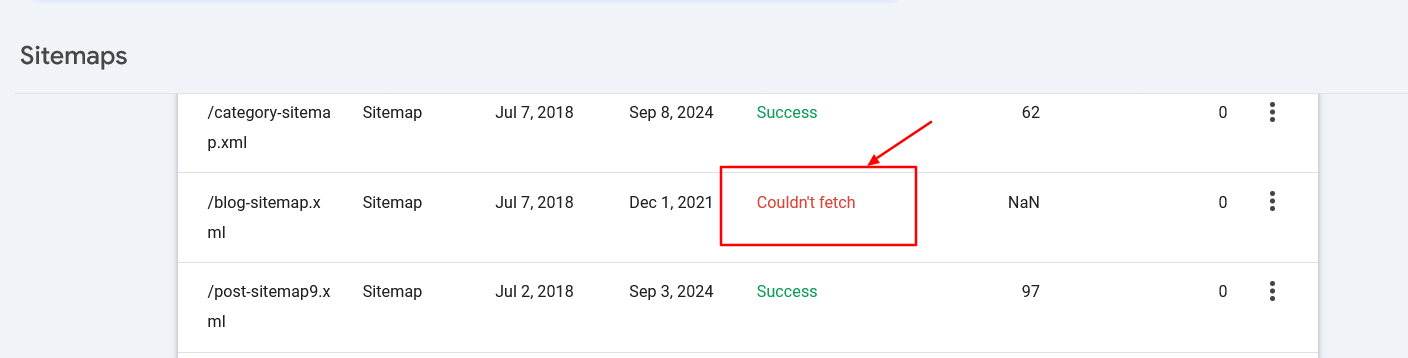
Pastikan URL peta situs dapat diakses oleh mesin pencari dan memiliki sintaksis yang tepat untuk menghindari kesalahan.
Kesalahan pengambilan peta situs di konsol pencarian
9. Kapan Menggunakan Crawl-Delay
Perintah crawl-delay dalam robots.txt menentukan jumlah detik yang harus ditunggu bot sebelum merayapi halaman berikutnya. Meskipun Googlebot tidak mengenali perintah crawl-delay, bot lain mungkin mematuhinya.
Ini membantu mencegah kelebihan beban server dengan mengendalikan seberapa sering bot menjelajahi situs Anda.
Misalnya, jika Anda ingin ClaudeBot merayapi konten Anda untuk pelatihan AI tetapi ingin menghindari kelebihan beban server, Anda dapat mengatur penundaan perayapan untuk mengelola interval antar permintaan.
User-agent: ClaudeBot
Crawl-delay: 60Ini menginstruksikan agen pengguna ClaudeBot untuk menunggu 60 detik di antara permintaan saat menjelajahi situs web.
Tentu saja, mungkin ada bot AI yang tidak mematuhi perintah penundaan perayapan. Dalam kasus tersebut, Anda mungkin perlu menggunakan firewall web untuk membatasi kecepatannya.
Pemecahan Masalah Robots.txt
Setelah Anda menyusun robots.txt, Anda dapat menggunakan alat ini untuk memecahkan masalah apakah sintaksnya benar atau apakah Anda tidak sengaja memblokir URL penting.
1. Validator Robots.txt Google Search Console
Setelah Anda memperbarui robots.txt, Anda harus memeriksa apakah robots.txt tersebut berisi kesalahan atau secara tidak sengaja memblokir URL yang ingin Anda jelajahi, seperti sumber daya, gambar, atau bagian situs web.
Navigasikan ke Setelan > robots.txt, dan Anda akan menemukan validator robots.txt bawaan. Berikut adalah video tentang cara mengambil dan memvalidasi robots.txt Anda.
2. Pengurai Robots.txt Google
Parser ini adalah parser robots.txt resmi Google yang digunakan di Search Console.
Diperlukan keterampilan tingkat lanjut untuk menginstal dan menjalankannya di komputer lokal Anda. Namun, sangat disarankan untuk meluangkan waktu dan melakukannya sesuai petunjuk di halaman tersebut karena Anda dapat memvalidasi perubahan dalam file robots.txt sebelum mengunggahnya ke server sesuai dengan parser resmi Google.
Manajemen Robots.txt Terpusat
Setiap domain dan subdomain harus memiliki robots.txt sendiri, karena Googlebot tidak mengenali robots.txt domain root untuk subdomain.
Ini menimbulkan tantangan ketika Anda memiliki situs web dengan selusin subdomain, karena itu berarti Anda harus mengelola banyak file robots.txt secara terpisah.
Namun, dimungkinkan untuk meng-host file robots.txt pada subdomain , seperti https://cdn.example.com/robots.txt, dan mengatur pengalihan dari https://www.example.com/robots.txt ke sana.
Anda dapat melakukan sebaliknya dan menghostingnya hanya di bawah domain root dan mengalihkan dari subdomain ke root.
Mesin pencari akan memperlakukan berkas yang dialihkan seolah-olah berkas tersebut berada di domain root. Pendekatan ini memungkinkan pengelolaan terpusat aturan robots.txt untuk domain utama dan subdomain Anda.
Ini membantu membuat pembaruan dan pemeliharaan lebih efisien. Jika tidak, Anda perlu menggunakan file robots.txt terpisah untuk setiap subdomain.
Kesimpulan
File robots.txt yang dioptimalkan dengan benar sangat penting untuk mengelola anggaran perayapan situs web . File ini memastikan bahwa mesin pencari seperti Googlebot menghabiskan waktu mereka pada halaman yang berharga daripada membuang-buang sumber daya pada halaman yang tidak perlu.
Di sisi lain, memblokir bot AI dan scraper menggunakan robots.txt dapat secara signifikan mengurangi beban server dan menghemat sumber daya komputasi.
Pastikan Anda selalu memvalidasi perubahan Anda guna menghindari masalah perayapan yang tidak terduga.
Namun, ingatlah bahwa meskipun memblokir sumber daya yang tidak penting melalui robots.txt dapat membantu meningkatkan efisiensi perayapan, faktor utama yang memengaruhi anggaran perayapan adalah konten berkualitas tinggi dan kecepatan pemuatan halaman.



{kind=link}
{kind=link}