
Ada banyak hal yang perlu diketahui tentang maksud pencarian, mulai dari penggunaan pembelajaran mendalam untuk menyimpulkan maksud pencarian dengan mengklasifikasikan teks dan memecah judul SERP menggunakan teknik Pemrosesan Bahasa Alami (NLP), hingga pengelompokan berdasarkan relevansi semantik , dengan manfaatnya yang dijelaskan.
Kami tidak hanya mengetahui manfaat dari menguraikan maksud pencarian, tetapi kami juga memiliki sejumlah teknik yang dapat kami gunakan untuk skala dan otomatisasi.
Jadi, mengapa kita memerlukan artikel lain tentang mengotomatiskan maksud pencarian?
Maksud pencarian menjadi semakin penting sekarang karena pencarian AI telah hadir.
Walaupun umumnya lebih banyak di era pencarian 10 tautan biru, hal yang sebaliknya berlaku dengan teknologi pencarian AI, karena platform ini umumnya berupaya meminimalkan biaya komputasi (per FLOP) untuk memberikan layanan.
SERP Masih Mengandung Wawasan Terbaik untuk Maksud Pencarian
Teknik yang digunakan sejauh ini melibatkan pembuatan AI sendiri, yaitu mendapatkan semua salinan dari judul konten pemeringkatan untuk kata kunci tertentu lalu memasukkannya ke dalam model jaringan saraf (yang kemudian harus Anda bangun dan uji) atau menggunakan NLP untuk mengelompokkan kata kunci.
Bagaimana jika Anda tidak memiliki waktu atau pengetahuan untuk membangun AI Anda sendiri atau menggunakan Open AI API?
Sementara kesamaan kosinus telah disebut-sebut sebagai jawaban untuk membantu profesional SEO menavigasi pembatasan topik untuk taksonomi dan struktur situs, saya tetap berpendapat bahwa pengelompokan pencarian berdasarkan hasil SERP merupakan metode yang jauh lebih unggul.
Itu karena AI sangat ingin mendasarkan hasilnya pada SERP dan untuk alasan yang baik – AI dimodelkan pada perilaku pengguna.
Ada cara lain yang menggunakan AI milik Google untuk melakukan pekerjaan untuk Anda, tanpa harus mengikis semua konten SERP dan membangun model AI.
Mari kita asumsikan bahwa Google memberi peringkat URL situs berdasarkan kemungkinan konten tersebut memenuhi permintaan pengguna dalam urutan menurun. Oleh karena itu, jika maksud dari dua kata kunci tersebut sama, maka SERP kemungkinan besar akan serupa.
Selama bertahun-tahun, banyak profesional SEO membandingkan hasil SERP untuk kata kunci guna menyimpulkan maksud penelusuran bersama (atau bersama) untuk tetap mengikuti pembaruan inti, jadi ini bukanlah hal baru.
Nilai tambah di sini adalah otomatisasi dan penskalaan perbandingan ini, yang menawarkan kecepatan dan presisi yang lebih tinggi.
Cara Mengelompokkan Kata Kunci Berdasarkan Maksud Pencarian dalam Skala Besar Menggunakan Python (Dengan Kode)
Dengan asumsi Anda memiliki hasil SERP dalam unduhan CSV, mari impor ke buku catatan Python Anda.
1. Impor Daftar Ke Buku Catatan Python Anda
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input['Unnamed: 0']
serps_input
Di bawah ini adalah berkas SERP yang sekarang diimpor ke kerangka data Pandas.
Gambar dari penulis, April 2025
2. Filter Data Untuk Halaman 1
Kami ingin membandingkan hasil Halaman 1 setiap SERP antara kata kunci.
Kita akan membagi kerangka data menjadi kerangka data kata kunci mini untuk menjalankan fungsi penyaringan sebelum menggabungkannya kembali menjadi kerangka data tunggal, karena kita ingin menyaring pada tingkat kata kunci:
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] <= k_urls]
return filtered_df
filtered_serps = serps_grpby_keyword.apply(filter_k_urls)
# Combine
## Add prefix to column names
#normed = normed.add_prefix('normed_')
# Concatenate with initial data frame
filtered_serps_df = pd.concat([filtered_serps],axis=0)
del filtered_serps_df['keyword']
filtered_serps_df = filtered_serps_df.reset_index()
del filtered_serps_df['level_1']
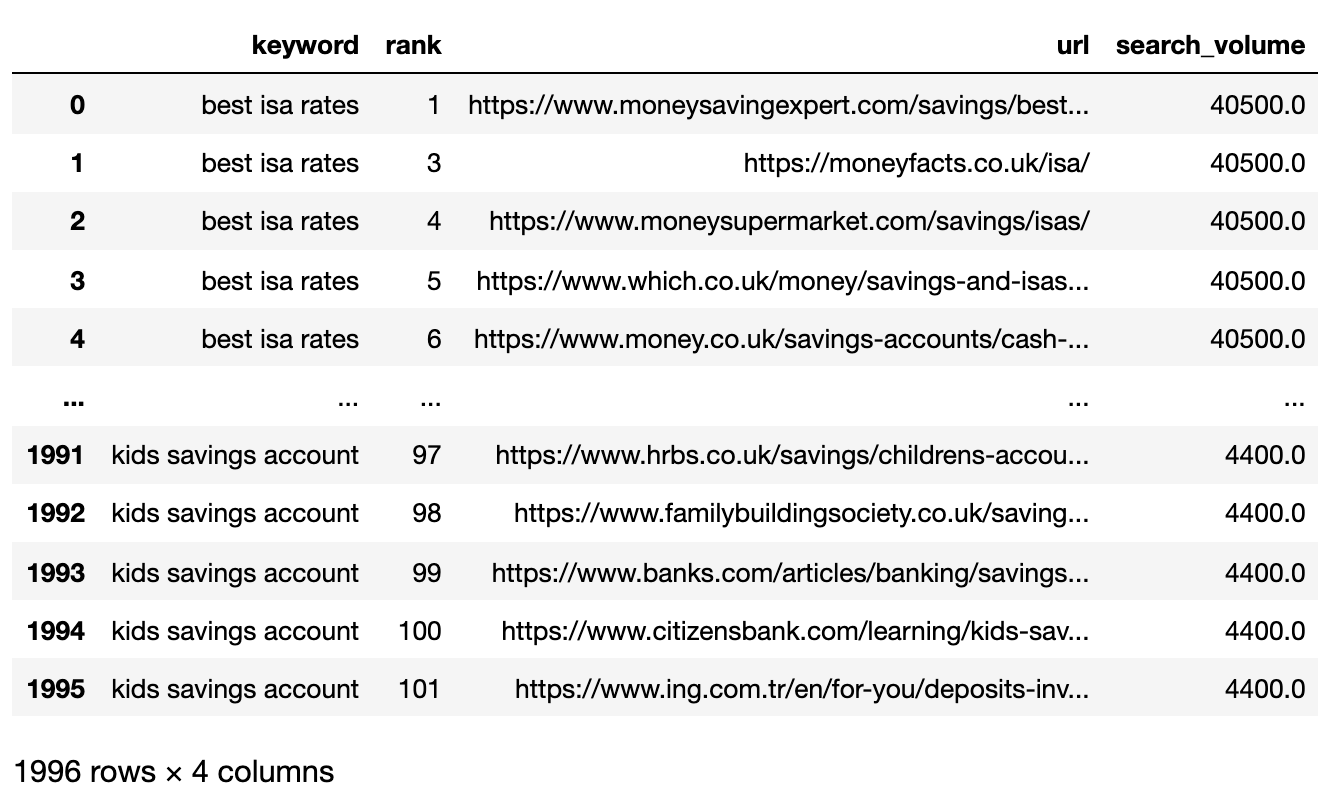
filtered_serps_df
Gambar dari penulis, April 2025
3. Ubah URL Peringkat Menjadi String
Karena ada lebih banyak URL hasil SERP daripada kata kunci, kita perlu mengompres URL tersebut menjadi satu baris untuk mewakili SERP kata kunci.
Begini caranya:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df['serp_string'] = ''.join(df['url'])
return df # Combine strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
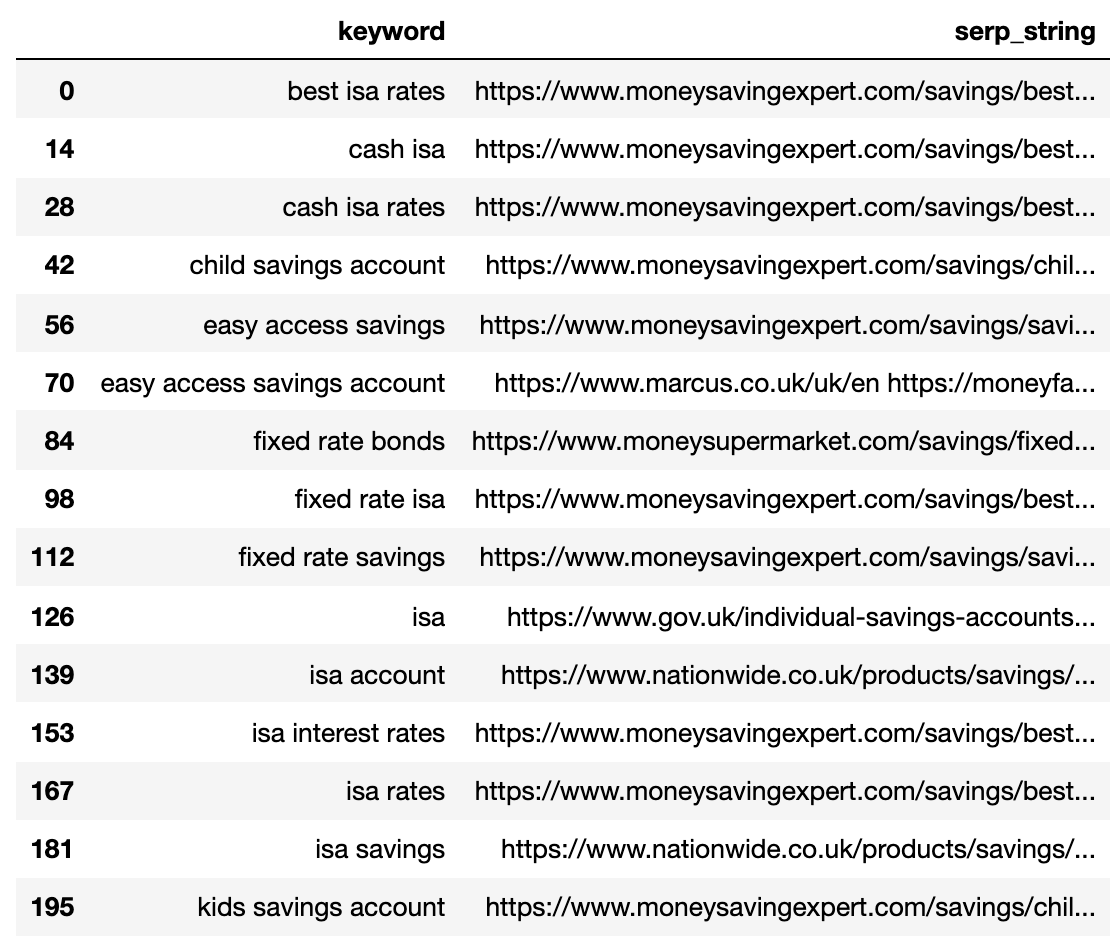
strung_serps
Di bawah ini menunjukkan SERP yang dikompresi menjadi satu baris untuk setiap kata kunci.
Gambar dari penulis, April 2025
4. Bandingkan Jarak SERP
Untuk melakukan perbandingan, sekarang kita perlu setiap kombinasi kata kunci SERP dipasangkan dengan pasangan lainnya:
# align serps
def serps_align(k, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'keyword': 'keyword_a'})
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword'})
return prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
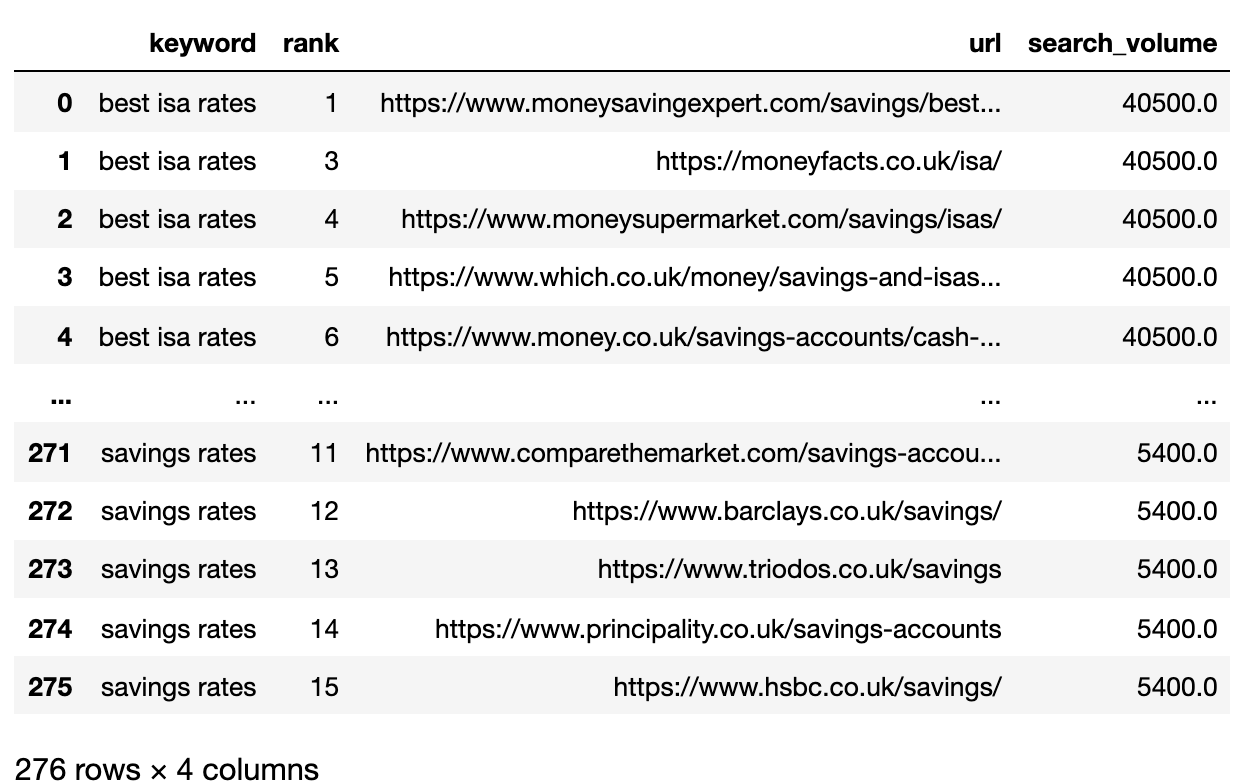
matched_serps

Di atas menunjukkan semua kombinasi pasangan kata kunci SERP, membuatnya siap untuk perbandingan string SERP.
Tidak ada pustaka sumber terbuka yang membandingkan objek daftar berdasarkan urutan, jadi fungsinya telah ditulis untuk Anda di bawah ini.
Fungsi “serp_compare” membandingkan tumpang tindih situs dan urutan situs tersebut antara SERP.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
#get positions of matches
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
#positions intersections of form [(pos_1, pos_2), ...]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps[['keyword', 'keyword_b', 'si_simi']]

Sekarang setelah perbandingan telah dijalankan, kita dapat mulai mengelompokkan kata kunci.
Kami akan menangani kata kunci apa pun yang memiliki kesamaan tertimbang sebesar 40% atau lebih.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NAN
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
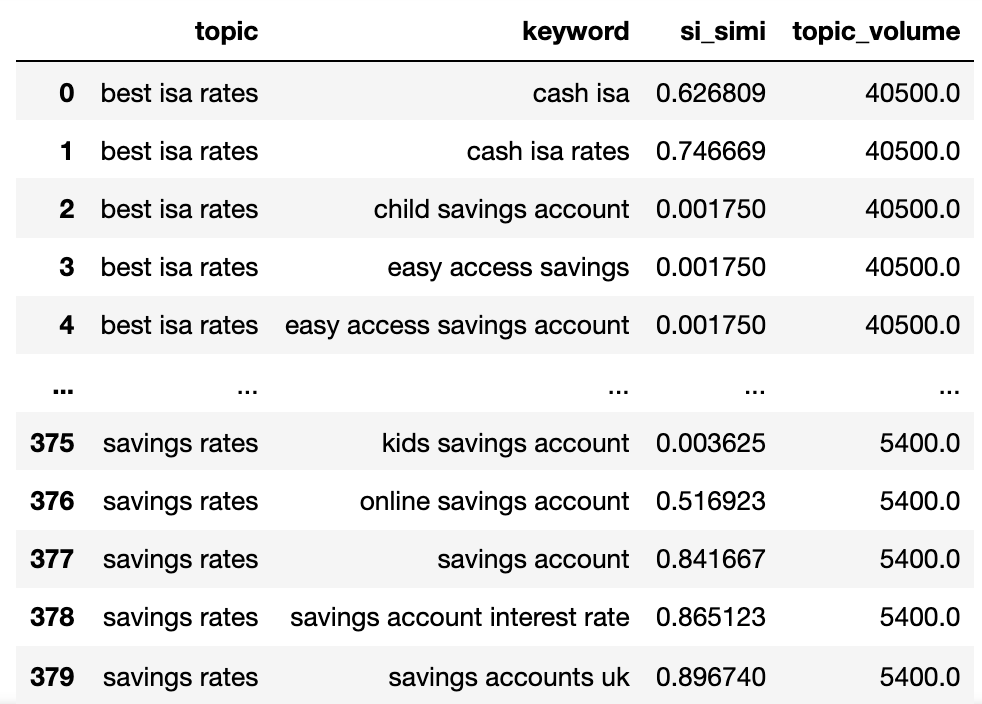
Sekarang kita memiliki nama topik potensial, kesamaan SERP kata kunci, dan volume pencarian masing-masing.
Anda akan melihat bahwa kata kunci dan kata kunci_b telah diubah namanya masing-masing menjadi topik dan kata kunci.
Sekarang kita akan mengulangi kolom-kolom dalam kerangka data menggunakan teknik lambda.
Teknik lambda merupakan cara yang efisien untuk mengulang baris dalam kerangka data Pandas karena teknik ini mengubah baris menjadi daftar, bukan fungsi .iterrows().
Ini dia:
queries_in_df = list(set(matched_serps['keyword'].to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups[keyw] = [keyw]
sim_topic_groups[keyw] = [topc]
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups[d_key].append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups[d_key].append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups[keyw].append(topc)
sim_topic_groups[keyw].append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups[topc].append(keyw)
sim_topic_groups[topc].append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]):
sim_topic_groups[keyw].append(topc)
[sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)]
sim_topic_groups.pop(topc)
elif len(sim_topic_groups[keyw]) < len(sim_topic_groups[topc]):
sim_topic_groups[topc].append(keyw)
[sim_topic_groups[topc].append(x) for x in sim_topic_groups.get(keyw)]
sim_topic_groups.pop(keyw)
elif len(sim_topic_groups[keyw]) == len(sim_topic_groups[topc]):
if sim_topic_groups[keyw] == topc and sim_topic_groups[topc] == keyw:
sim_topic_groups.pop(keyw)
elif si < simi_lim:
if (not dict_key(non_sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups,keyw)):
non_sim_topic_groups[keyw] = [keyw]
if (not dict_key(non_sim_topic_groups, topc)) and (not dict_key(sim_topic_groups, topc)) and (not dict_values(sim_topic_groups,topc)):
non_sim_topic_groups[topc] = [topc]
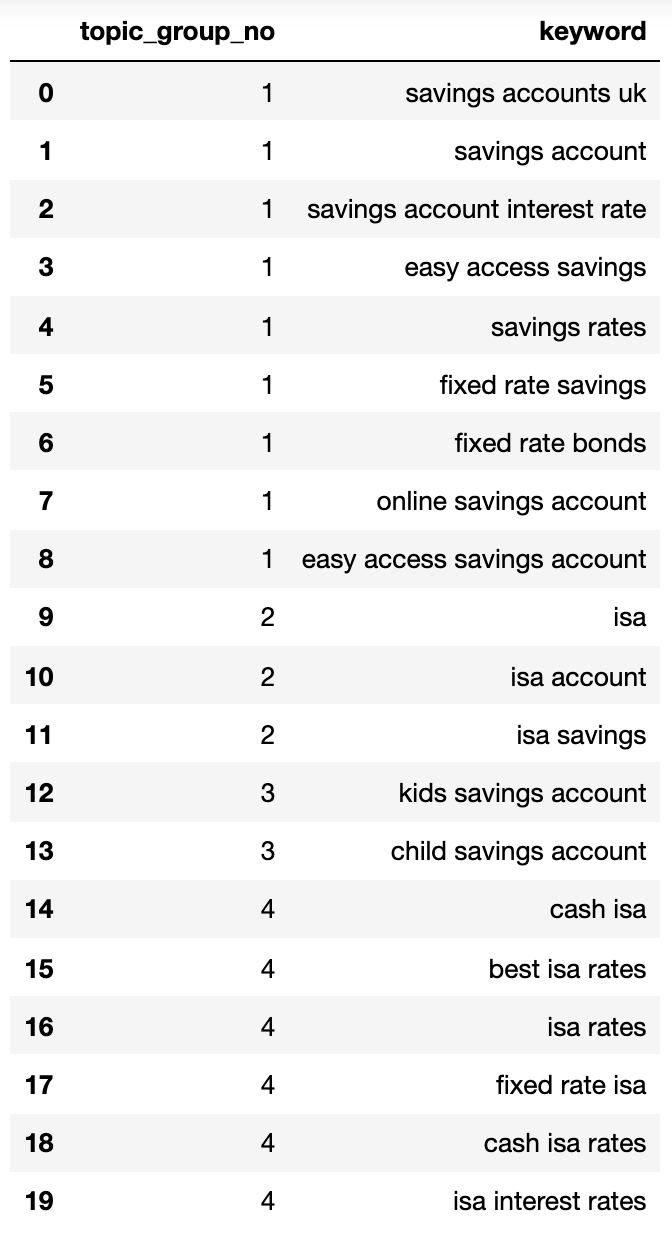
Di bawah ini menunjukkan kamus yang berisi semua kata kunci yang dikelompokkan berdasarkan maksud pencarian ke dalam kelompok bernomor:
{1: ['fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'],
2: ['child savings account', 'kids savings account'],
3: ['savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'],
4: ['isa account', 'isa', 'isa savings']}Mari kita masukkan ke dalam kerangka data:
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
Gambar dari penulis, April 2025
Kelompok maksud pencarian di atas menunjukkan perkiraan yang baik tentang kata kunci di dalamnya, sesuatu yang mungkin dicapai oleh pakar SEO.
Meskipun kami hanya menggunakan sekumpulan kata kunci yang kecil, metode ini jelas dapat ditingkatkan hingga ribuan (bahkan lebih).
Mengaktifkan Output Untuk Membuat Pencarian Anda Lebih Baik
Tentu saja, hal di atas dapat dikembangkan lebih jauh dengan menggunakan jaringan saraf, memproses konten pemeringkatan untuk klaster dan penamaan grup klaster yang lebih akurat, sebagaimana yang telah dilakukan beberapa produk komersial di pasaran.
Untuk saat ini, dengan keluaran ini, Anda dapat:
- Gabungkan ini ke dalam sistem dasbor SEO Anda sendiri untuk membuat tren dan pelaporan SEO Anda lebih bermakna.
- Bangun kampanye pencarian berbayar yang lebih baik dengan menyusun akun Google Ads Anda berdasarkan maksud pencarian untuk mendapatkan Skor Kualitas yang lebih tinggi.
- Gabungkan URL pencarian e-dagang yang redundan.
- Susun taksonomi situs belanja berdasarkan maksud pencarian, bukan berdasarkan katalog produk pada umumnya.
Saya yakin masih banyak lagi aplikasi yang belum saya sebutkan – silakan berkomentar tentang aplikasi penting mana saja yang belum saya sebutkan.
Apa pun masalahnya, riset kata kunci SEO Anda menjadi sedikit lebih terukur, akurat, dan cepat!



{kind=link}
{kind=link}
{kind=link}
{kind=link}